














Tu Guía Completa para Usar Inteligencia Artificial en tu PC con LM Studio
Utilizar la IA de forma local conlleva beneficios significativos. En primer lugar, la privacidad y seguridad son primordiales, ya que los datos procesados permanecen en la máquina del usuario, mitigando preocupaciones sobre el uso de información sensible por terceros. Esto es especialmente relevante cuando se manejan datos confidenciales. Como se destaca, «El uso de IA offline ofrece importantes ventajas, como una mayor privacidad y seguridad, ya que los datos procesados no requieren una conexión a la nube, lo que reduce el riesgo de fugas o accesos no autorizados».
Además, la IA offline otorga autonomía y control, eliminando la dependencia de una conexión a internet o de la disponibilidad de servidores externos. Esto significa que se puede acceder a la IA en cualquier momento y lugar. Otro aspecto relevante es la ausencia de costos recurrentes; una vez configurado el sistema, no existen tarifas de suscripción o pagos por API para el uso básico. Finalmente, la ejecución local abre la puerta a una mayor personalización y experimentación con los modelos, y puede ofrecer una baja latencia, ya que las respuestas se procesan directamente en el hardware del usuario.
Para aquellos que deseen explorar este fascinante mundo, existen diversas herramientas. Este artículo se centrará en LM Studio, una aplicación que destaca por su facilidad de uso, especialmente para principiantes que buscan iniciarse en la IA local.
LM Studio al Descubierto: Tu Centro de IA Personal
LM Studio se presenta como una aplicación de escritorio diseñada específicamente para descubrir, descargar y ejecutar Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) de manera local en ordenadores personales, siendo compatible con Windows, Mac y Linux. Su propósito fundamental es simplificar la experimentación con estos complejos modelos, haciéndolos accesibles incluso para usuarios sin una profunda experiencia técnica. Se le ha descrito como un «patio de recreo local para la IA» («Your Local AI Playground» ) y su interfaz gráfica amigable es uno de sus mayores atractivos.
Entre sus funcionalidades estrella se encuentran:
- Ejecución local de LLMs: Es el corazón de su propuesta. Todo el procesamiento ocurre enteramente en la máquina del usuario.
- Interfaz de chat intuitiva: Similar a la de aplicaciones conocidas como ChatGPT, lo que facilita enormemente la interacción con los modelos cargados.
- Descubrimiento y descarga de modelos: Se integra con Hugging Face, una vasta biblioteca de modelos de IA de código abierto, permitiendo a los usuarios acceder y descargar una gran variedad de LLMs.
- Servidor API local compatible con OpenAI: Esta característica avanzada permite a los desarrolladores integrar los LLMs que se ejecutan localmente en sus propias aplicaciones, scripts y flujos de trabajo personalizados.
- Gestión de modelos y configuraciones: Facilita la organización de los modelos descargados y el ajuste de sus parámetros de ejecución.

En cuanto a la compatibilidad con modelos, LM Studio soporta principalmente modelos en el formato GGUF. Este es el sucesor del formato GGML y está optimizado para su uso con llama.cpp, una librería que permite ejecutar LLMs de manera eficiente en hardware de consumo. LM Studio puede ejecutar una amplia gama de LLMs populares, incluyendo, pero no limitado a, Llama, Mistral, Phi-2, Gemma, DeepSeek y Orca. Para usuarios de Mac con procesadores Apple Silicon (M1, M2, etc.), LM Studio también ofrece compatibilidad con modelos en formato MLX, el framework de aprendizaje automático de Apple.
La existencia de LM Studio es particularmente significativa en el contexto actual del desarrollo de la IA. La comunidad de código abierto está produciendo un flujo constante y creciente de LLMs potentes y diversos. Sin embargo, ejecutar estos modelos a menudo requiere una considerable pericia técnica: configurar entornos de desarrollo, compilar código fuente (como el de llama.cpp) y gestionar complejas dependencias de software. LM Studio actúa como un puente crucial, abstrayendo gran parte de esta complejidad. Al proporcionar una interfaz gráfica de usuario para descargar y ejecutar estos modelos , y al utilizar llama.cpp y MLX como motores de inferencia optimizados, LM Studio reduce drásticamente la barrera de entrada. Esto permite que una audiencia mucho más amplia, no solo ingenieros de aprendizaje automático, pueda acceder y utilizar los avances más recientes en IA de código abierto, fomentando así una mayor experimentación e innovación a nivel global.
Preparando el Terreno: Instalación de LM Studio Paso a Paso (Tutorial Exhaustivo)
Antes de sumergirse en el mundo de la IA local con LM Studio, es crucial asegurarse de que el sistema cumple con los requisitos necesarios y seguir el proceso de instalación adecuado.
A. Requisitos del Sistema: ¿Tu PC está listo para la IA Local?
Para un funcionamiento óptimo de LM Studio, el hardware y software del ordenador deben cumplir ciertas especificaciones. A continuación, se detallan los requisitos:
- Sistemas Operativos Compatibles:
- Windows: Versiones x86/ARM64, con un procesador que soporte AVX2.
- macOS: Requiere procesadores Apple Silicon (M1, M2, M3, M4). Para Macs con procesadores Intel, aunque Msty se menciona como alternativa , LM Studio podría funcionar si se cumplen otros requisitos. Se especifica macOS 11.0 (Big Sur) o posterior.
- Linux: Distribuciones x64, con un procesador que soporte AVX2.
- Procesador (CPU): Es indispensable que el procesador sea compatible con AVX2 (Advanced Vector Extensions 2). Se puede verificar esta compatibilidad en las especificaciones del fabricante (Intel ARK o el sitio de AMD). Se recomienda un procesador moderno, como un Ryzen 5 o equivalente de generación reciente, con al menos 4 núcleos y 8 hilos.
- Memoria RAM:
- Mínimo: 8GB son suficientes para modelos muy pequeños y pruebas iniciales.
- Recomendado: 16GB o más para la mayoría de los modelos y para asegurar un funcionamiento fluido. El programa en sí puede llegar a utilizar hasta 8GB de memoria.
- Óptimo: 32GB o más para modelos de lenguaje grandes.
- Tarjeta Gráfica (GPU) y VRAM:
- Aunque opcional, una GPU dedicada es altamente recomendada para acelerar la inferencia (la generación de respuestas).
- LM Studio es compatible con GPUs NVIDIA (a través de CUDA) y AMD (experimentalmente con ROCm). Las GPUs NVIDIA RTX muestran mejoras significativas de rendimiento.
- Se recomiendan al menos 6GB de VRAM. La cantidad de VRAM disponible determinará cuántas capas del modelo se pueden descargar a la GPU para su procesamiento rápido.
- Espacio en Disco Duro:
- La aplicación LM Studio en sí misma ocupa aproximadamente 400MB.
- Los modelos LLM son archivos grandes, que pueden variar desde 2GB hasta más de 20GB cada uno.
- Se recomienda el uso de una unidad de estado sólido (SSD) para una carga más rápida de los modelos y de la aplicación.
- Es necesario disponer de espacio suficiente no solo para los modelos que se deseen descargar, sino también para la caché del programa.
A continuación, se presenta una tabla resumen para facilitar la comprobación de los requisitos:
Tabla: Requisitos del Sistema para LM Studio
| Componente | Requisito Mínimo | Requisito Recomendado |
|---|---|---|
| Sistema Operativo | Windows (AVX2), macOS (Apple Silicon), Linux (AVX2) | Las versiones más recientes de los SO compatibles |
| CPU | Compatible con AVX2 | Procesador moderno (4+ núcleos, 8+ hilos), AVX2 |
| RAM | 8GB | 16GB o más |
| GPU (VRAM) | No requerida (CPU fallback) | NVIDIA/AMD con 6GB+ VRAM |
| Espacio en Disco | Espacio para LM Studio + 1 modelo pequeño (ej. 5GB) | SSD con espacio para múltiples modelos (ej. 50GB+) |
B. Descarga e Instalación: Guía para Cada Sistema Operativo
Una vez verificados los requisitos, el siguiente paso es descargar e instalar LM Studio.
- Paso 1: Visita la Web Oficial.
- Acceder al sitio web oficial de LM Studio: https://lmstudio.ai/.
- Localizar la sección de descargas («Download») en la página principal.
- Paso 2: Descarga el Instalador para tu SO.
- Seleccionar y descargar la versión correspondiente para Windows, macOS o Linux.
- Es importante asegurarse de que la configuración del navegador o del antivirus no bloquee la descarga de archivos ejecutables.
- Paso 3: Instalación.
- Windows:
- Ejecutar el archivo
.exedescargado. - Seguir las instrucciones del instalador. Generalmente, se pueden dejar las opciones de instalación predeterminadas.
- Ejecutar el archivo
- macOS:
- Abrir el archivo
.dmgdescargado. - Arrastrar el icono de LM Studio a la carpeta de «Aplicaciones».
- Si aparece una advertencia indicando que el desarrollador no está verificado, se debe hacer clic derecho sobre el icono de LM Studio, seleccionar «Abrir» y confirmar la acción.
- Abrir el archivo
- Linux:
- El instalador para Linux suele ser un archivo
.AppImage. - Otorgar permisos de ejecución al archivo descargado. Abrir una terminal en la ubicación del archivo y ejecutar:
sudo chmod +x LM-Studio-VERSION.AppImage(reemplazandoLM-Studio-VERSION.AppImagecon el nombre real del archivo). - Para una mejor integración y para evitar posibles problemas con el sandbox, se puede extraer el AppImage. Desde la terminal:
./LM-Studio-VERSION.AppImage --appimage-extract. Esto creará una carpeta llamadasquashfs-root. Navegar a esta carpeta (cd squashfs-root) y ejecutar los siguientes comandos:sudo chown root:root chrome-sandboxysudo chmod 4755 chrome-sandbox. Finalmente, se puede ejecutar LM Studio con./lm-studiodesde esta carpeta. - Puede ser necesario instalar algunas dependencias adicionales. Un comando común para sistemas basados en Debian/Ubuntu es:
sudo apt install libatk1.0-0 libatk-bridge2.0-0 libcups2 libgdk-pixbuf2.0-0 libgtk-3-0 libpango-1.0-0 libcairo2 libxcomposite1 libxdamage1 libasound2t64 libatspi2.0-0.
- El instalador para Linux suele ser un archivo
- Windows:
C. Primer Vistazo a LM Studio: Navegando la Interfaz
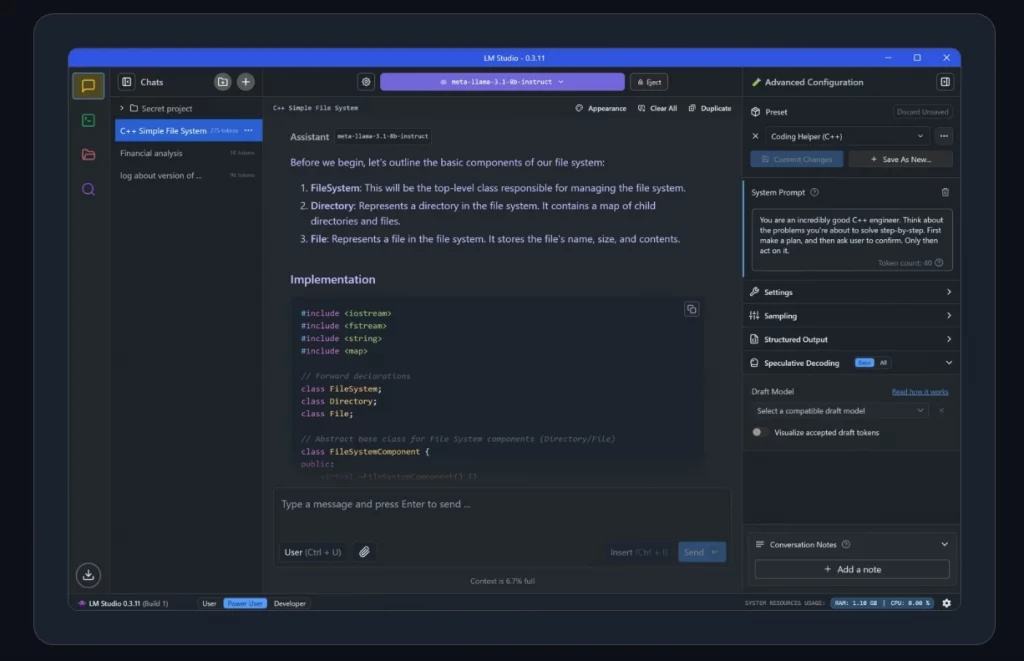
Al iniciar LM Studio por primera vez, se presenta una pantalla de bienvenida. La interfaz está diseñada para ser intuitiva. Los elementos principales se encuentran generalmente en un panel a la izquierda:
- Lupa (🔍 – Discover/Búsqueda): Es el punto de partida para encontrar y descargar nuevos modelos de IA.
- Bocadillo de Chat (💬 – Chat): Una vez que un modelo está cargado, esta es la sección donde se interactúa con él, enviando prompts y recibiendo respuestas.
- Carpeta (📁 – My Models/Mis Modelos): Aquí se pueden ver y gestionar todos los modelos que se han descargado localmente.
- Servidor Local (🔌 o similar – Local Server): Permite iniciar un servidor API para que otras aplicaciones puedan comunicarse con los modelos cargados en LM Studio.
- Ajustes (⚙️ – Settings/Configuration): Desde aquí se accede a las configuraciones generales de la aplicación y a parámetros específicos de los modelos.
La interfaz gráfica de LM Studio, con su clara separación de funciones (descubrimiento de modelos, chat, gestión de modelos), es una elección de diseño deliberada. Su objetivo es facilitar la incorporación de usuarios con diversos niveles de habilidad técnica, ocultando eficazmente las complejidades subyacentes de la ejecución de LLMs.
Tradicionalmente, trabajar con LLMs locales implicaba el uso de herramientas de línea de comandos y configuraciones manuales , lo cual representa una barrera para usuarios no técnicos o aquellos que buscan una configuración más rápida. LM Studio, al utilizar iconos familiares y una disposición que separa la adquisición de modelos (🔍) de la interacción (💬) y la gestión (📁), refleja la experiencia de usuario de IAs de chat populares basadas en la nube. Esto hace que la transición a la IA local sea menos intimidante. Incluso las funciones avanzadas, como el servidor local o la configuración de modelos , son accesibles a través de elementos de la GUI en lugar de depender exclusivamente de código o comandos. Este diseño es un facilitador clave para el objetivo de LM Studio de democratizar el acceso a los LLM locales, haciendo que la tecnología avanzada se sienta accesible y manejable.
Tu Primer Modelo IA Offline: Descarga y Puesta en Marcha con LM Studio (Tutorial)
Con LM Studio instalado, el siguiente paso es descargar y ejecutar un modelo de lenguaje. Este tutorial guiará a través del proceso utilizando Mistral 7B Instruct (Q4_K_M) como ejemplo, una opción equilibrada para principiantes.
A. El Arte de Encontrar Modelos: La Pestaña de Búsqueda (🔍)
Al hacer clic en el icono de la lupa (🔍) en el panel izquierdo, se accede a la interfaz de búsqueda de modelos. Aquí se pueden encontrar:
- Modelos Destacados («Staff Picks»): Una selección curada por el equipo de LM Studio.
- Búsqueda en Hugging Face: Permite buscar directamente en el extenso repositorio de Hugging Face. La barra de búsqueda es útil para encontrar modelos específicos por su nombre, como «Mistral», «Llama 3» o «Phi-2». LM Studio mostrará diferentes versiones y, crucialmente, diferentes cuantizaciones de los modelos disponibles. Es importante prestar atención a las indicaciones de LM Studio, ya que a menudo sugiere qué modelos son compatibles o recomendados para el sistema del usuario basándose en el hardware detectado.
B. Eligiendo tu Modelo Inicial: Ejemplo con Mistral 7B Instruct (Q4_K_M)

Para este tutorial, se utilizará el modelo Mistral 7B Instruct con la cuantización Q4_K_M.
- ¿Por qué este modelo para empezar?
- Capacidad y Tamaño: Mistral 7B Instruct es un modelo de 7 mil millones de parámetros (7B) que ofrece un excelente rendimiento para su tamaño, siendo muy competente en tareas de chat y seguimiento de instrucciones. Los modelos de 7B ofrecen un buen equilibrio entre capacidades y requisitos de recursos para hardware de consumo.
- Versión «Instruct»: Esta variante está específicamente afinada (fine-tuned) para comprender y seguir instrucciones, lo que la hace ideal para aplicaciones de tipo chatbot.
- Entendiendo la Cuantización GGUF: ¿Qué significa «Q4_K_M»?
- GGUF: Es el formato de archivo que utiliza LM Studio, diseñado para ser eficiente y contener toda la información necesaria del modelo (pesos, metadatos, tokenizador) en un solo archivo. Está optimizado para su uso con
llama.cpp. - Cuantización: Es un proceso que reduce la precisión numérica de los pesos (parámetros) del modelo. Esto disminuye significativamente el tamaño del archivo del modelo en disco y la cantidad de memoria RAM necesaria para ejecutarlo. La contrapartida es una posible, aunque idealmente pequeña, pérdida en la calidad de las respuestas del modelo. Como se explica, «La cuantización reduce la precisión de los números en un modelo, intercambiando un poco de precisión por enormes ganancias en tamaño y velocidad».
- Q4_K_M: Este sufijo describe el tipo específico de cuantización:
Q4: Indica que los pesos del modelo se han cuantizado a 4 bits._K: Se refiere a un conjunto de métodos de cuantización más modernos (K-Quants) que generalmente ofrecen una mejor calidad en comparación con los métodos más antiguos para el mismo número de bits._M: Indica un tamaño de bloque «Medio» (Medium) utilizado durante el proceso de cuantización. Esta opción suele ofrecer el mejor equilibrio entre el nivel de compresión (reducción de tamaño) y la preservación de la calidad del modelo. Se describe K_M como «Un gran equilibrio de velocidad, uso de memoria y calidad de salida. Es el ‘punto medio seguro’ para la mayoría de los usuarios».
- Impacto: Un modelo como Mistral 7B Instruct cuantizado a Q4_K_M será considerablemente más pequeño y requerirá menos RAM que su versión original sin cuantizar (FP16 o FP32), haciéndolo viable para ejecutarse en ordenadores personales estándar. Específicamente, el archivo
mistral-7b-instruct-v0.1.Q4_K_M.gguftiene un tamaño aproximado de 4.37 GB y requiere unos 6.87 GB de RAM si no se utiliza la descarga a GPU (GPU offload).
- GGUF: Es el formato de archivo que utiliza LM Studio, diseñado para ser eficiente y contener toda la información necesaria del modelo (pesos, metadatos, tokenizador) en un solo archivo. Está optimizado para su uso con
Para ayudar a los principiantes a tomar una decisión informada, la siguiente tabla compara algunas cuantizaciones comunes para el modelo Mistral 7B:
Tabla: Comparativa Rápida de Cuantizaciones Comunes para Mistral 7B (GGUF)
| Tipo de Cuantización (Ejemplo) | Tamaño Aprox. Archivo (GB) | RAM Estimada Necesaria (GB) (sin offload GPU) | Calidad/Caso de Uso Típico |
|---|---|---|---|
| …Q2_K.gguf | 3.08 | 5.58 | El más pequeño, pérdida de calidad significativa, no recomendado |
| …Q3_K_M.gguf | 3.52 | 6.02 | Muy pequeño, alta pérdida de calidad |
| …Q4_K_M.gguf | 4.37 | 6.87 | Medio, calidad equilibrada – recomendado para empezar |
| …Q5_K_M.gguf | 5.13 | 7.63 | Grande, muy baja pérdida de calidad, buena opción si hay RAM |
| …Q5_K_S.gguf | 5.00 | 7.50 | Grande, baja pérdida de calidad |
| …Q6_K.gguf | 5.94 | 8.44 | Muy grande, pérdida de calidad extremadamente baja |
| …Q8_0.gguf | 7.70 | 10.20 | Muy grande, calidad casi original, requiere mucha RAM |
- Proceso de Descarga del Modelo Seleccionado:
- En la pestaña de búsqueda (🔍) de LM Studio, buscar «Mistral 7B Instruct».
- En la lista de archivos del modelo (probablemente bajo el repositorio de «TheBloke» o similar, que proporciona muchas versiones GGUF), localizar el archivo que termina en
Q4_K_M.gguf. Por ejemplo,mistral-7b-instruct-v0.1.Q4_K_M.gguf. - Hacer clic en el botón «Download» (Descargar) situado junto a este archivo.
- La descarga comenzará. Se puede monitorizar el progreso en la pestaña «Downloads» (icono de flecha hacia abajo en la parte inferior izquierda). Dado que el archivo es de aproximadamente 4.37 GB, la descarga puede llevar algún tiempo dependiendo de la velocidad de internet.
C. ¡A Conversar! Cargando y Ejecutando el Modelo
Una vez que la descarga del modelo ha finalizado:
- Navegar a la pestaña «My Models» (Mis Modelos), identificada con un icono de carpeta (📁) en la barra lateral izquierda.
- En la lista de modelos descargados, se debería ver el modelo Mistral 7B Instruct (por ejemplo, bajo
TheBloke/Mistral-7B-Instruct-v0.1-GGUF) y el archivo específico.ggufque se descargó. - Hacer clic sobre el nombre del modelo para seleccionarlo. A la derecha de la interfaz, aparecerán opciones y detalles sobre el modelo.
- Para cargar el modelo e iniciar un chat, se puede hacer clic en el botón «Start New Chat» o similar, o asegurarse de que el modelo esté seleccionado en el menú desplegable en la parte superior de la pantalla de chat si ya se está en esa pestaña. También puede haber un botón «Load» (Cargar).
- El modelo comenzará a cargarse en la memoria RAM del ordenador (y en la VRAM de la GPU si se configura el offload). Este proceso puede tardar desde unos segundos hasta un minuto, dependiendo del tamaño del modelo y la velocidad del sistema.
- Una vez que el modelo esté completamente cargado, la interfaz de chat estará activa y lista para que se escriba el primer prompt (instrucción o pregunta).
Aunque LM Studio simplifica enormemente el proceso de selección y carga de modelos, es fundamental que los usuarios comprendan las implicaciones del tamaño del modelo y el tipo de cuantización en relación con su hardware específico. LM Studio puede ofrecer «suposiciones» sobre la compatibilidad , pero la decisión final recae en el usuario. Intentar cargar un modelo Q8_0 de Mistral 7B (que requiere unos 10GB de RAM ) en un sistema con solo 8GB de RAM probablemente resultará en problemas de rendimiento o errores, incluso si LM Studio permitió la descarga. Por lo tanto, incluso con una herramienta tan amigable, existe una necesidad subyacente de que el usuario se eduque sobre estos conceptos para asegurar experiencias exitosas y satisfactorias con los LLMs locales. Este tutorial busca, en parte, cubrir esa necesidad informativa.
Dominando LM Studio: Interactúa y Configura tu IA
Una vez que el modelo está cargado, es hora de interactuar con él y aprender a ajustar su comportamiento. LM Studio ofrece una interfaz de chat y varias opciones de configuración accesibles.
A. El Chat: Tu Lienzo de Interacción
La pestaña de Chat (💬) es el espacio principal para la comunicación con el LLM.
- Enviar Prompts: Se escriben las preguntas, instrucciones o cualquier texto que se desee que el modelo procese en el cuadro de texto situado en la parte inferior de la interfaz y se presiona Enter.
- Interpretar Respuestas: El modelo generará una respuesta basada en el prompt, la cual aparecerá en la ventana de chat, similar a una conversación.
- Panel de Configuración (Contextual): Generalmente situado a la derecha de la ventana de chat, este panel permite ajustar diversos parámetros que influyen en cómo el modelo genera las respuestas. Los parámetros más importantes para principiantes son:
- System Prompt (Instrucción de Sistema / Pre-prompt):
- Este es un texto que se proporciona al modelo antes de la primera interacción del usuario. Define el rol, la personalidad, el tono o las directrices generales que el LLM debe seguir. Ejemplos: «Eres un asistente virtual experto en cocina internacional», «Actúa como un pirata espacial divertido y sarcástico», «Proporciona respuestas concisas y directas».
- LM Studio puede tener una plantilla de prompt preconfigurada basada en los metadatos del modelo, pero esta se puede personalizar. Para una edición más avanzada de la plantilla, se puede ir a «My Models» (📁), hacer clic en el icono de engranaje (⚙️) junto al modelo deseado y buscar las opciones de plantilla de prompt.
- Temperature (Temperatura):
- Este parámetro controla la aleatoriedad o «creatividad» de las respuestas del modelo. Un valor más bajo (por ejemplo, 0.2 a 0.5) hará que las respuestas sean más deterministas, enfocadas y predecibles. Un valor más alto (por ejemplo, 0.7 a 1.0) fomentará respuestas más creativas, diversas e inesperadas, pero también puede aumentar la probabilidad de que el modelo genere información menos coherente o factual. Para respuestas claras, un valor alrededor de 0.7 o 0.8 suele ser un buen punto de partida.
- Context Length (Longitud de Contexto /
n_ctx):- Define la cantidad de información (medida en tokens, que son aproximadamente palabras o partes de palabras) que el modelo «recuerda» de la conversación actual. Esto incluye tanto los prompts del usuario como las respuestas anteriores del modelo.
- Una longitud de contexto mayor permite conversaciones más largas y coherentes, ya que el modelo tiene acceso a más historial. Sin embargo, un contexto más largo también consume más memoria RAM. Cada modelo tiene una longitud de contexto máxima que puede manejar.
- Este valor se puede ajustar, pero no se debe exceder el máximo soportado por el modelo cargado. Un valor común para empezar podría ser 4096 tokens.
- GPU Offload (Capas en GPU /
n_gpu_layers):- Si se dispone de una tarjeta gráfica (GPU) compatible y con suficiente VRAM, este control deslizante (o numérico) permite descargar una parte o la totalidad de las capas computacionales del modelo a la VRAM de la GPU.
- Cómo ajustar: Se desliza el control o se introduce un número para indicar cuántas capas del modelo se enviarán a la GPU. LM Studio puede mostrar una estimación de la VRAM que se utilizará.
- Beneficio: Descargar capas a la GPU puede acelerar significativamente la velocidad de generación de respuestas (inferencia).
- Precaución: Es crucial no exceder la cantidad de VRAM dedicada disponible en la GPU, ya que esto podría causar errores, una drástica ralentización (si el sistema empieza a usar memoria compartida o paginación) o incluso el cierre de la aplicación. Se recomienda dejar siempre un margen de VRAM para el contexto de la conversación y otras operaciones del sistema. LM Studio ofrece una opción para «Limitar la descarga del modelo a la memoria dedicada de la GPU» («Limit Model Offload to Dedicated GPU Memory») para GPUs NVIDIA, lo cual es útil.
- Si no se tiene una GPU, no se desea utilizarla, o la VRAM es muy limitada, este valor debe dejarse en 0. El modelo se ejecutará completamente en la CPU.
- Otros parámetros (Avanzados): Existen otros ajustes como Top-K, Top-P, penalización por repetición (Repeat Penalty), etc.. Para usuarios principiantes, centrarse en Temperatura y GPU Offload suele ser suficiente para empezar a experimentar.
- System Prompt (Instrucción de Sistema / Pre-prompt):
La disponibilidad de estos controles granulares directamente en la interfaz gráfica de LM Studio es una de sus grandes fortalezas. Permite a los usuarios realizar optimizaciones y experimentaciones sobre la marcha, fomentando una comprensión más profunda del comportamiento de los LLMs sin necesidad de editar archivos de configuración complejos o escribir código. Mientras que herramientas más orientadas a desarrolladores como Ollama a menudo requieren el uso de la línea de comandos o llamadas API para ajustar estos parámetros , LM Studio los expone de manera visual e interactiva. Este bucle de retroalimentación iterativo (cambiar un parámetro y ver el efecto inmediatamente) acelera el aprendizaje y permite a los usuarios adaptar el rendimiento y el estilo de salida del LLM a sus necesidades específicas para una tarea determinada, convirtiendo al LLM en una herramienta mucho más adaptable y personal.
B. Inteligencia Aumentada por Recuperación (RAG): Chatea con Tus Documentos
Una de las capacidades más potentes de LM Studio es la función de Retrieval Augmented Generation (RAG), que permite cargar documentos propios (como PDF, TXT, DOCX, CSV) para que el LLM los utilice como base de conocimiento al generar respuestas.
- Cómo funciona (de forma simplificada):
- El usuario puede arrastrar y soltar los archivos de documentos directamente en la interfaz de chat o utilizar una opción específica para adjuntarlos.
- LM Studio procesa estos documentos de manera completamente local; nada de la información contenida en ellos abandona el ordenador del usuario.
- Si el documento es suficientemente corto (es decir, si cabe en la ventana de contexto configurada para el modelo), LM Studio puede pasar su contenido completo al modelo. Esto es especialmente útil para modelos más nuevos que soportan tamaños de contexto más grandes.
- Si el documento es muy largo, LM Studio empleará técnicas de RAG. Esto implica «buscar» y extraer los fragmentos de texto más relevantes del documento (o de varios documentos) en relación con la pregunta o prompt del usuario, y luego proporcionar esos fragmentos al LLM como contexto adicional para que formule su respuesta.
- Límites: LM Studio permite cargar hasta 5 archivos a la vez, con un tamaño máximo combinado de 30MB.
- Beneficios: Esta funcionalidad es extremadamente útil para:
- Obtener respuestas basadas en información privada o específica contenida en los documentos del usuario.
- Resumir textos propios, informes, artículos de investigación, etc.
- Extraer datos específicos o responder preguntas sobre el contenido de los documentos.
- Todo esto se realiza de forma offline y segura, garantizando la privacidad de la información. La documentación de LM Studio enfatiza: «Todo el procesamiento de documentos se realiza localmente, y nada de lo que subas a LM Studio abandona la aplicación».
- Consejo para un RAG exitoso: Para obtener los mejores resultados al usar RAG, es recomendable ser lo más específico posible en las preguntas. Mencionar términos, ideas o palabras clave que se espera encontrar en el material fuente relevante a menudo aumenta la probabilidad de que el sistema proporcione el contexto más útil al LLM. Como siempre, la experimentación es la mejor manera de descubrir qué funciona mejor.
Desata tu Creatividad: Ideas Potentes para Proyectos con IA Offline
Ahora que se han cubierto los aspectos técnicos de instalación y configuración de LM Studio y un modelo LLM, es momento de explorar algunas ideas prácticas y creativas para empezar a utilizar la IA offline. Estos ejemplos están pensados para principiantes y pueden adaptarse fácilmente.
- Asistente de redacción y brainstorming:
- La IA local puede ser una excelente compañera para generar ideas para artículos de blog, historias cortas, nombres de proyectos, o incluso para superar el temido bloqueo del escritor.
- Prompt Ejemplo:
"Estoy escribiendo un ensayo sobre el impacto de las redes sociales en la comunicación interpersonal. Proporcióname 5 argumentos principales a favor y 5 en contra." - Prompt Ejemplo:
"Necesito ideas para un regalo de cumpleaños original para una persona aficionada a la jardinería y la tecnología. Dame 3 sugerencias creativas y poco comunes."
- Resumen inteligente de textos y documentos:
- Utilizando la función RAG de LM Studio, se pueden cargar documentos propios (artículos largos, capítulos de libros, informes) y pedirle al modelo que los resuma.
- Prompt Ejemplo (con un archivo PDF cargado sobre energías renovables):
"Resume los puntos clave de este documento sobre energía solar en un máximo de 200 palabras, destacando sus ventajas y desventajas." - Prompt Ejemplo (pegando un texto directamente en el chat):
"Resume el siguiente fragmento de noticias en una sola frase: [pegar aquí el fragmento de noticia]."
- Apoyo en programación básica y explicación de código:
- Los LLMs son sorprendentemente buenos explicando fragmentos de código en diversos lenguajes de programación o ayudando a generar código para tareas sencillas. Siempre se debe revisar y probar el código generado.
- Prompt Ejemplo:
"Explícame línea por línea qué hace esta función en Python y para qué podría servir: def calcular_media(lista_numeros): if not lista_numeros: return 0 return sum(lista_numeros) / len(lista_numeros)" - Prompt Ejemplo:
"Escribe un script corto en Bash que encuentre todos los archivos.txt en el directorio actual y sus subdirectorios, y cuente el número total de líneas en ellos."
- Herramienta de aprendizaje y explicación de conceptos:
- Se puede pedir al LLM que explique temas complejos de una manera sencilla y adaptada a un nivel de comprensión específico.
- También puede ayudar a generar preguntas o cuestionarios sobre un tema para facilitar el autoaprendizaje.
- Prompt Ejemplo:
"Explícame el concepto de 'Agujero Negro' como si se lo estuvieras contando a un niño de 8 años, usando analogías simples." - Prompt Ejemplo:
"Estoy aprendiendo sobre la Revolución Francesa. Genérame 5 preguntas de opción múltiple con sus respuestas correctas para repasar los eventos más importantes."
El verdadero potencial de los LLMs locales para principiantes no reside únicamente en replicar tareas que se pueden hacer con IAs en la nube, sino en la capacidad de permitir una experimentación altamente personalizada e iterativa en un entorno privado y sin costos adicionales por uso. Las IAs en la nube a menudo tienen límites de uso, costos asociados o preocupaciones de privacidad que pueden inhibir la experimentación libre, especialmente con datos personales. Los LLMs locales, accesibles a través de herramientas como LM Studio, eliminan estas barreras. Los usuarios pueden ajustar prompts, mensajes de sistema, parámetros del modelo (como la temperatura ) y observar los resultados de forma instantánea y repetida sin incurrir en gastos adicionales. Pueden utilizar la función RAG con sus propias notas, código o escritos para obtener asistencia altamente contextualizada. Esto crea un poderoso ciclo de retroalimentación para el aprendizaje (por ejemplo, comprender código, explorar conceptos) y la creatividad (por ejemplo, escritura, lluvia de ideas) que se adapta profundamente al contexto y ritmo individual del usuario. Este nivel de interacción personalizada e iterativa es un diferenciador clave de la IA local.
Balance Final: Ventajas y Desafíos de la IA en tu PC
Ejecutar modelos de IA localmente en el propio ordenador ofrece una serie de beneficios atractivos, pero también presenta ciertas consideraciones y desafíos que es importante tener en cuenta.
Recapitulando los Pros:
- Privacidad y Seguridad de Datos: El control total sobre la información es quizás la ventaja más destacada. Los datos no salen del equipo local.
- Autonomía y Acceso Offline: Independencia de la conexión a internet y de la disponibilidad de servicios de terceros.
- Sin Costos Recurrentes (para uso básico): Una vez configurado, el uso de los modelos no implica suscripciones ni tarifas por API, lo que puede suponer un ahorro considerable a largo plazo.
- Personalización y Experimentación: Mayor libertad para modificar parámetros, probar diferentes modelos y adaptar la IA a necesidades específicas.
- Baja Latencia Potencial: Al procesarse localmente, las respuestas pueden ser más rápidas, especialmente si se cuenta con hardware adecuado.
Consideraciones y Desafíos:
- Requisitos de Hardware: Se necesita un ordenador personal relativamente potente, especialmente en términos de RAM (16GB o más recomendados) y un procesador con soporte AVX2. Una GPU dedicada, aunque opcional, mejora significativamente el rendimiento. Esto puede ser una barrera de entrada para usuarios con equipos más antiguos o modestos.
- Configuración y Mantenimiento: Aunque herramientas como LM Studio simplifican enormemente el proceso, la responsabilidad de la descarga, instalación, gestión de modelos, actualizaciones de software y la posible resolución de problemas técnicos recae enteramente en el usuario [ (curva de aprendizaje), (configuración compleja)].
- Rendimiento y Capacidades de los Modelos: Los modelos locales, especialmente las versiones cuantizadas diseñadas para ejecutarse en hardware de consumo, pueden no ser tan potentes o tener las mismas capacidades de razonamiento complejo que los modelos más grandes y costosos disponibles a través de APIs en la nube [ («Menos potencia que la nube»)].
- Actualizaciones de Modelos: El campo de los LLMs evoluciona rápidamente. Mantenerse al día con los modelos más recientes, sus nuevas versiones o cuantizaciones optimizadas requiere que el usuario esté atento y realice las descargas e instalaciones correspondientes.
- Consumo de Energía: Ejecutar LLMs, especialmente si se utiliza la GPU de forma intensiva, puede incrementar el consumo de energía del ordenador.
Embarcarse en el viaje de la IA local implica un intercambio: los usuarios ganan un control y una privacidad significativos, pero también asumen responsabilidades que normalmente manejan los proveedores de servicios en la nube. Estos últimos se encargan del aprovisionamiento de hardware, las actualizaciones de los modelos y gran parte de la sobrecarga operativa. Al optar por la IA local , el usuario es ahora responsable de asegurar que su hardware cumple los requisitos , de descargar y gestionar los archivos de los modelos y, potencialmente, de solucionar problemas técnicos. Si bien herramientas como LM Studio facilitan enormemente estas tareas , la responsabilidad fundamental cambia de manos. Este cambio empodera a los usuarios con un control sin precedentes , pero también exige un mayor nivel de compromiso y comprensión técnica (o la voluntad de aprender) en comparación con el uso pasivo de un servicio web.
Conclusión: El Futuro de la IA está (También) en Tus Manos
La inteligencia artificial offline, impulsada por herramientas accesibles como LM Studio, ya no es un concepto reservado para expertos en tecnología. Se ha convertido en una realidad tangible que empodera a los usuarios, ofreciéndoles un control sin precedentes sobre sus datos y sus interacciones con la IA. La capacidad de ejecutar modelos de lenguaje potentes directamente en el ordenador personal abre un abanico de posibilidades para la creatividad, el aprendizaje y la productividad, todo ello bajo un paraguas de privacidad y autonomía.
Se invita a todos los interesados a sumergirse en la experimentación. La curiosidad y el aprendizaje continuo son claves en este campo en rápida evolución. Para aquellos que comienzan, la comunidad de LM Studio, accesible a través de plataformas como Discord , puede ser un recurso invaluable para obtener ayuda, compartir conocimientos y conectar con otros entusiastas y desarrolladores.
Comparte este contenido:











Publicar comentario